Genauigkeitsquote und Vollständigkeitsquote (Recall and Precision)
Die Statische Code-Analyse untersucht Quell- oder Binärcode ohne das dieser ausgeführt wird und findet potenzielle Fehler und Schwachstellen. Problemstellen können durch die Statische Analyse genau lokalisiert und selbst dann aufgedeckt werden wenn sie in "entfernten" Codestellen liegen. Da die Statische Analyse den Code nicht ausführt, kann diese bereits früh im Entwicklungsprozess eingesetzt werden. In der frühen Projektphase sind die Kosten für das Aufdecken und Fixen von Fehlern und Schwachstellen noch relativ gering.Automatisierte Statische Analysetools haben allerdings auch einen Nachteil: sie liefern False Positives und False Negatives.
Was heißt das?
Fehlermeldungen können wie folgt klassifiziert werden:
- True Positive - ein wirklicher Fehler wurde angezeigt.
- False Positive - es wurde ein Fehler angezeigt, der aber in der Realität keiner ist.
- False Negative - ein Fehler wurde bei der Analyse "übersehen" und dementsprechend nicht angezeigt.
- True Negative - ein nicht vorhandener Fehler wird nicht angezeigt - das Tool löst also keinen "Fehlalarm" aus.
Die Qualität von Statischen Codeanalysetools wird unter anderem durch die Vollständigkeitsquote (Recall) und die Genauigkeitsquote (Precision) bestimmt.
Vollständigkeitsquote (Recall) und Genauigkeitsquote (Precision) bestimmen sich aus den Verhältnissen zwischen True Positives, Fales Positives, False Negatives und True Negatives wie folgt:
Vollständigkeitsquote (Recall) = Anzahl von True Positives / Anzahl von True Positives + Anzahl von False Negatives
Genauigkeitsquote (Precision) = Anzahl von True Positives / Anzahl von True Positives + Anzahl von False Positives
Ein perfektes Werkzeug hätte eine perfekte Vollständigkeitsquote (Wert 1, also keine False Negatives) und eine perfekte Genauigkeitsquote (Wert 1, also keine False Positives).
Mit aktuell verfügbaren Analysetools ist es leider nicht möglich, beides optimal zu erreichen.
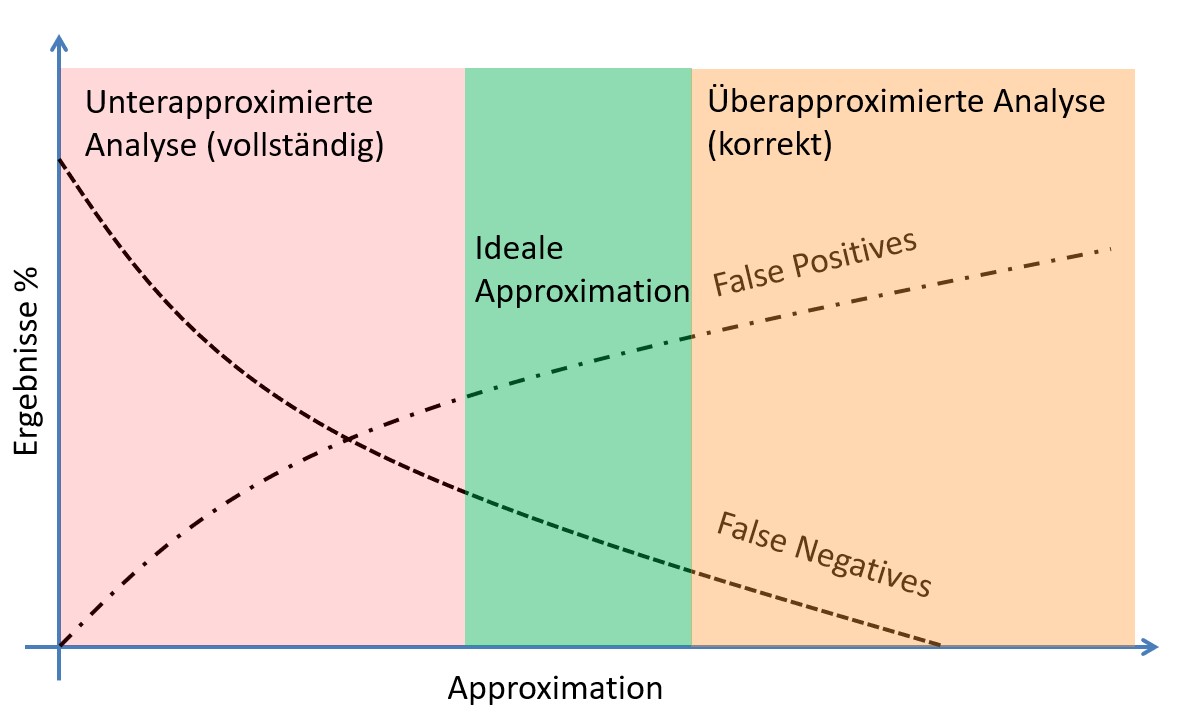
Vollständige vs. korrekte Analyse
Es gibt jedoch Analysetools, die sich einer solchen optimalen Analyse annähern.Unterapproximierende Analysen sind vollständig: sie melden wenige bis keine False Positives, jedoch eine hohe Anzahl von False Negatives. (Fast) alle Fehler, die angezeigt werden sind tätsächliche Fehler, allerdings wir eine hohe Zahl von Fehlern nicht erkannt.
Bei überapproximierenden Analysen ist die Anzahl der False Negatives gering. Allerdings gibt es eine hohe Anzahl von False Positives. Es werden (fast) alle Fehler gefunden, allerdings gibt es viele "Fehlalarme", die alle überprüft werden müssen.
Für die Praxis liegt der beste "Kompromiss" in der Mitte: relativ wenige False Positives und relativ wenige Fales Negatives. Es werden also nur wenige Fehler übersehen - gleichzeitig gibt es nur eine geringe Zahl von "Fehlalarmen".
Das Statische Codeanalysetool CodeSonar von CodeSecure bietet eine solche optimierte Analyse.
Video: Klassifizierung von Warnungen / vollständige vs. korrekte Analyse






